Autoencoder vs PCA vs t-SNE vs UMAP
차원축소 방법, 무엇을 언제 써야 할까?
“압축이 목적이냐, 시각화가 목적이냐”
들어가며
고객 임베딩, 행동 임베딩, LLM 벡터…
차원이 512, 768, 1024쯤 되면
반드시 이 질문이 나온다.
“이걸 사람의 눈으로 보려면 차원수를 2차원 또는 3차원으로 줄여야 하지 않을까?”
“다른 모델의 입력으로 임베딩을 사용하려고 하는데 차원수를 줄이고 싶은데?”
그리고 후보는 보통 네 가지다.
- PCA
- t-SNE
- UMAP
- Autoencoder
하지만 이 네 가지는 목적 자체가 다르다.
한 문장 요약
PCA는 선형 압축,
t-SNE/UMAP은 시각화,
Autoencoder는 학습 기반 비선형 압축이다.
1. 한눈에 비교
|
방법 |
선형성 |
국소 보존 |
전역 보존 |
거리 해석 가능성 |
속도 |
|---|---|---|---|---|---|
|
PCA |
선형 |
낮음 |
높음 |
가능 |
매우 빠름 |
|
t-SNE |
비선형 |
매우 높음 |
거의 없음 |
불가 |
느림 |
|
UMAP |
비선형 |
높음 |
중간 |
부분 가능 |
빠름 |
|
AutoEncoder |
비선형 |
학습 의존 |
학습 의존 |
모델 의존 |
중간 |
2. PCA (Principal Component Analysis)
원리
- 먼저 데이터의 분산이 가장 큰 방향을 찾는다.
- 그리고 그 방향 축(선형 축)을 따라 차원 축소.
고차원 벡터
→ 공분산 행렬
→ 고유벡터 추출
→ 상위 k개 축 선택특징
- 빠름
- 해석 가능 (분산 기준)
- 복원 가능
- (X) 비선형 구조 반영 불가
언제 쓰나?
- 노이즈 제거
- 선형 모델 입력을 위한 전단 처리
3. t-SNE (t-distributed Stochastic Neighbor Embedding)
원리
- “가까운 점은 가깝게”
- “먼 점은 적당히”
확률 분포를 매칭해 2D/3D로 매핑.
특징
- 클러스터 시각화 매우 뛰어남
- 로컬 구조 보존
- (X) 전역 거리 왜곡
- (X) 대규모 데이터에 느림
- (X) 새 데이터 추가 어려움
언제 쓰나?
- 클러스터 구조 확인
- 고객 그룹 시각화
4. UMAP (Uniform Manifold Approximation and Projection)
원리
- 데이터가 저차원 다양체(manifold)에 있다고 가정
- 근접 그래프를 구성해 보존
특징
- t-SNE보다 빠름
- 전역 구조 비교적 유지
- 대규모 데이터 가능
- (X) 완전한 거리 보존은 아님
- (X) 복원 불가
언제 쓰나?
- 대규모 고객 시각화
- LLM 임베딩 2D projection
- 클러스터 구조 탐색
5. Autoencoder
원리
신경망으로 압축-복원 학습.
Input (768)
↓
Encoder
↓
Latent (k)
↓
Decoder
↓
Reconstruction특징
- 비선형 구조 학습 가능
- 복원 가능
- 목적 맞춤 설계 가능
- (X) 학습과정이 별도로 필요
- (X) 과적합 위험
- (X) 튜닝 비용 있음
언제 쓰나?
- 임베딩 압축 후 재사용
- 노이즈 제거
- downstream task 최적화
- 의미 구조를 보존하면서 압축
6. 본질적 차이: “목적”
PCA / Autoencoder
-> 압축(Compression)이 목적
t-SNE / UMAP
-> 시각화(Visualization)가 목적
7. 고객 임베딩 관점에서 비교
(1) 단순 차원 축소 후 모델링
→ PCA 권장
(빠르고 안정적)
(2) 고객 군집 구조 시각화
→ UMAP 권장
(t-SNE는 느림)
(3) 의미 구조 유지하면서 압축
→ Autoencoder
(특히 LLM 임베딩 압축 시)
(4) 실시간 서비스 환경
→ PCA
(Autoencoder는 모델 로딩 필요)
8. 중요한 오해 하나
t-SNE/UMAP에서 멀어 보인다고
실제 고차원 공간에서도 멀다는 보장은 없다.
시각화는:
“구조를 보기 위한 도구”
“정확한 거리 계산 도구”가 아니다.
9. LLM / BFM 임베딩에 적용하면?
- 임베딩 의미축 해석 → PCA
- 세그먼트 분리 확인 → t-SNE
- 전체 구조 + 세그먼트 동시 확인 → UMAP (추천)
- 의미 압축 + 예측용 latent 생성 → AutoEncoder
10. 계산 복잡도 관점
|
방법 |
계산 비용 |
|---|---|
|
PCA |
O(n·d²) |
|
t-SNE |
O(n²) |
|
UMAP |
O(n log n) |
|
Autoencoder |
학습 비용 O(epoch·n) |
n이 크면
t-SNE는 거의 불가능해진다.
10. 시각화 예시
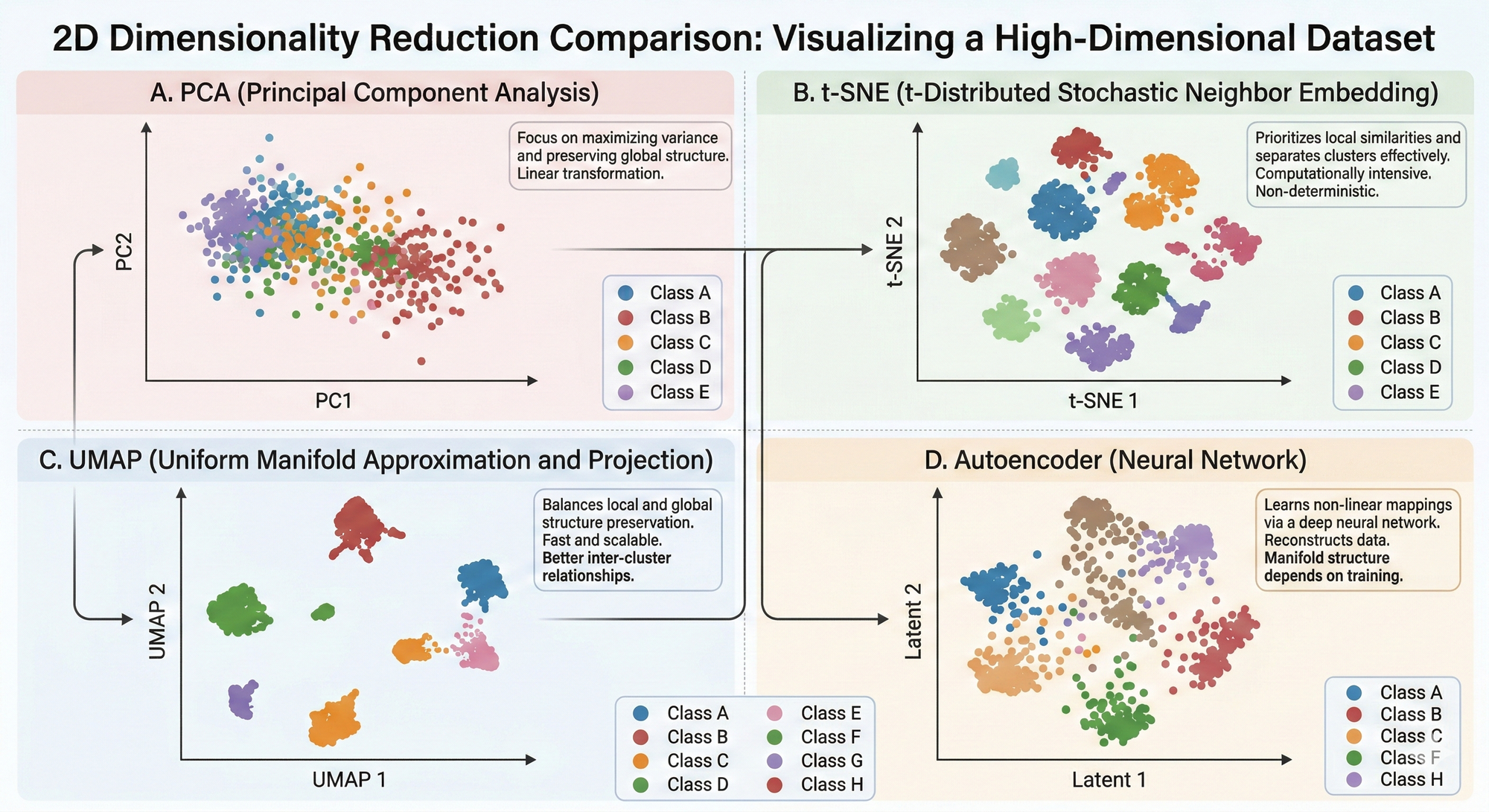
한 문장으로 정리하면
PCA는 빠르게 글로벌 구조 확인(단, 군집의 수나 뭉침 정도 확인이 어려울 수 있으며, 비선형적 특성 보전은 안됨에 유의),
t-SNE/UMAP은 군집의 수나 뭉침 정도 확인용 시각화(글로벌 구조 확인은 아님),
Autoencoder는 비선형적 특성을 보전하면 압축 가능(단, 학습이 선행되어야 하는 단점)
목적이 다르면 선택도 달라진다.
마치며
차원축소는 “좋은 그림을 만드는 기술”이 아니다.
목적에 맞는 정보 손실을 설계하는 일이다.
- 시각화를 원하면 UMAP
- 빠른 전처리를 원하면 PCA
- 의미를 보존한 압축이 필요하면 Autoencoder