고객 스코어링 방식의 결정적 차이 : 의미 축(axis) vs 앵커 벡터(anchor)
“방향으로 잴 것인가, 기준점과의 거리로 잴 것인가”
들어가며
고객 임베딩을 스코어링할 때 흔히 사용하는 방법은
의미 축(axis)에 투영하는 방식이다.
하지만 다른 방법도 있다.
“특정 기준 고객(또는 기준 문장)을 하나 정해두고
그 벡터와의 유사도로 스코어링하면 안 될까?”
이게 바로 앵커 벡터 기반 스코어링이다.
둘은 비슷해 보이지만,
철학과 수학적 성격이 완전히 다르다.
한 문장 요약
의미 축은 ‘방향’을 기준으로 스코어링하고,
앵커 벡터는 ‘특정 기준점과의 유사도’를 기준으로 스코어링한다.
1. 정의부터 명확히 하자
(1) 의미 축(axis) 기반 스코어링
축은 보통 이렇게 만든다.
axis = mean(High Group) - mean(Low Group)
score = dot(v_customer, axis)-> 양극 대비(contrast) 로 정의된 방향
(2) 앵커 벡터(anchor) 기반 스코어링
앵커는 이렇게 만든다.
anchor = embedding("프리미엄 제품을 선호하는 고객")
score = cosine(v_customer, anchor)-> 하나의 기준 상태(reference state)
시각적으로는 아래와 같이 표현된다.
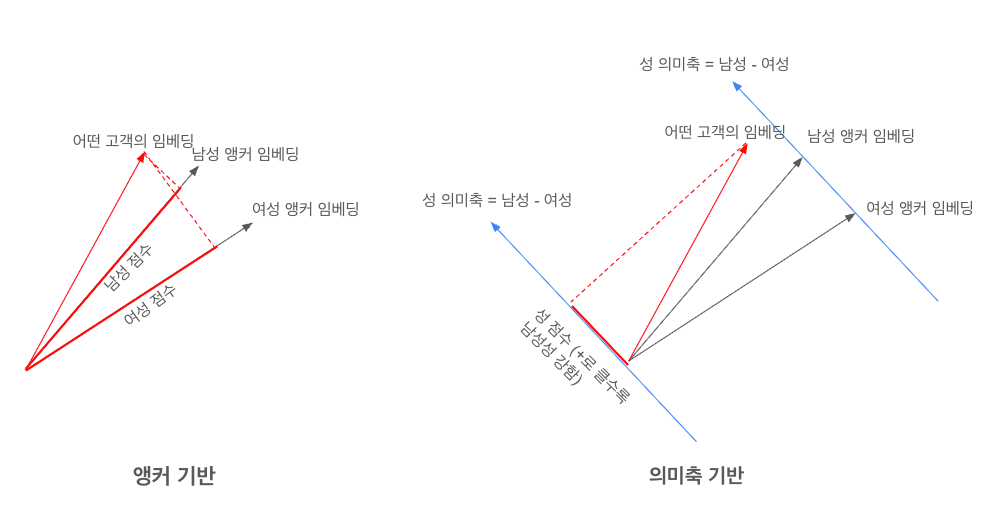
2. 수학적으로 무엇이 다른가?
의미 축은 “선형 분리 방향”
- 중심은 0
- 양/음 방향 존재
- 대비 구조
앵커는 “거리 기반”
- 기준점과의 유사도
- 음/양 개념 없음
- 방향성보다 proximity
3. 개념적 차이
|
항목 |
의미 축 |
앵커 벡터 |
|---|---|---|
|
기준 |
두 집단 대비 |
하나의 기준점 |
|
방향성 |
있음 |
없음 |
|
양/음 해석 |
가능 |
어려움 |
|
선형 분리 |
강함 |
제한적 |
|
해석 안정성 |
비교적 높음 |
앵커 정의에 의존 |
4. 언제 의미 축이 더 좋은가?
이런 상황
- “구매 vs 비구매”처럼 명확한 대비
- 연속적 스코어 필요
- 임계값 기반 운영
- 선형 분리 성능 중요
-> 비즈니스 의사결정에 적합
5. 언제 앵커가 더 좋은가?
이런 상황
- 라벨이 없음
- 특정 고객 유형과의 유사도만 알고 싶음
- zero-shot 분석
- 빠른 프로토타이핑
예:
anchor = embedding("대형 가전을 선호하는 4인 가족 고객")-> 페르소나 유사도 분석에 적합
6. 해석 관점에서의 결정적 차이
의미 축
“이 고객은 구매의사 방향으로
얼마나 이동했는가?”
→ 상태 변화 해석 가능
앵커
“이 고객은
특정 기준 고객과 얼마나 비슷한가?”
→ 군집 유사도 해석
7. 안정성 차이
의미 축은 보통:
- 두 집단 평균 기반
- 데이터 변화에 비교적 강함
앵커는:
- 특정 벡터에 강하게 의존
- 앵커 선택이 바뀌면 결과 급변
-> 앵커는 설계 민감도가 높다.
8. 혼합 전략이 가장 강력하다
실무에서는 이렇게 쓰는 경우가 많다.
의미 축 → 1차 필터링
앵커 유사도 → 세부 페르소나 매칭또는
여러 앵커 벡터를 묶어
축처럼 구성9. 중요한 통찰
의미 축은:
“이 문제를 어떻게 자를 것인가?”
앵커는:
“이 고객은 누구와 닮았는가?”
질문이 다르다.
10. 흔한 오해
(X) 앵커 유사도가 높으면 그 성향이 강하다
→ 반드시 그렇지 않다 (단일 기준 문제)
(X) 의미 축이 항상 더 과학적이다
→ 라벨 품질에 따라 달라진다
(X) 둘 중 하나만 써야 한다
→ 대부분 혼합이 최적
11. 앵커 벡터 여러개를 조합하는 방법
앵커를 사용할 때의 한계는 앞서 설명했듯 분명하다.
- 기준점 하나에 과도하게 의존
- 양/음 방향이 없음
- 대비 구조가 약함
그래서 등장하는 아이디어가 이것이다.
“앵커 여러 개를 조합해서
의미 축(axis)처럼 쓸 수는 없을까?”
가능하다.
그렇게 만든 축을 여기서는 pseudo-axis라고 부르자.
방법 1. Positive 앵커 평균
여러 개의 긍정 앵커를 평균낸다.
A_pos = mean([
embedding("프리미엄 제품 선호"),
embedding("고가 제품 구매 이력"),
embedding("브랜드 충성 고객")
])그리고:
score = dot(v_customer, A_pos)-> 단일 앵커보다 안정적 하지만 아직 방향은 아니다
이 방식은 여전히 “유사도”다. 반대 방향이 없다.
아래와 같이 대비구조를 추가한다.
방법 2. Positive − Negative 앵커
이게 가장 강력한 방식이다.
A_pos = mean(긍정 앵커들)
A_neg = mean(반대 앵커들)
pseudo_axis = normalize(A_pos - A_neg)이제 스코어는:
score = dot(v_customer, pseudo_axis)-> 양/음 해석 가능
-> 축 구조 완성
예시: 구매의사 pseudo-axis
A_pos:
- "곧 구매하려는 고객"
- "장바구니에 상품을 담고 결제 직전인 상태"
- "구매 의도가 매우 높은 사용자"
A_neg:
- "단순 탐색 고객"
- "정보만 확인하는 사용자"
- "구매 의사가 낮은 상태"하지만, 모든 앵커가 동일하게 중요하지 않다.
pseudo_axis =
w1 * anchor1
+ w2 * anchor2
- w3 * anchor3
- w4 * anchor4가중치는:
- 전문가 판단
- 데이터 기반 최적화
- 작은 선형 모델 학습
-> semi-supervised 방식 가능
앵커를 생성하는 방법
방법 1. 클러스터 중심 사용
- 고객 클러스터링
- 특정 클러스터 중심을 앵커로 지정
방법 2. 대표 샘플 평균
- 상위 5% 구매 직전 고객 평균
- 하위 5% 탐색 고객 평균
그러나 여전히 아래와 같은 위험이 있다.
(X) 앵커 설계에 매우 민감
(X) 데이터 분포 반영이 제한적
(X) 과도한 주관성 위험
(X) 고차원 왜곡 가능
-> 정규화 및 검증 필수
검증 방법
- 극단값 샘플 점검
Top / Bottom 고객 직접 확인 - 단순 분류 성능 확인
pseudo-axis score 하나로 구매 예측 가능 여부 확인 - 앵커 제거 민감도 테스트
앵커 하나 제거했을 때 결과 급변하면 불안정
한 문장으로 정리하면
의미 축은 ‘대비 기반 방향 스코어’이고,
앵커는 ‘기준점 유사도 스코어’다.
무엇을 묻느냐에 따라 선택이 달라진다.
마치며
고객을 스코어링하는 방식은
결국 이 질문으로 귀결된다.
- 우리는 상태 변화를 측정하려는가?
- 아니면 특정 유형과의 유사도를 보고 싶은가?
전자는 의미 축,
후자는 앵커 벡터가 적합하다.
그리고 가장 정교한 시스템은
둘을 함께 사용한다.